
Matt Glickman
Chief Executive Officer
LinkedIn
An industry leader in enterprise data platforms, Matt led the development of business-critical analytics at Goldman Sachs for over 20 years. He later joined Snowflake to run Product Management and launched the Snowflake Data Marketplace. Now, he is bringing AI workers to enterprises to power the new AI economy.
.jpg)
Justin Langseth
Chief Technology Officer
LinkedIn
At Snowflake, Justin helped launch the data marketplace and worked on the AI strategy. Before that, he co-founded and led several companies, including Zoomdata and Clarabridge. He holds 51 technology patents related to data sharing, protection, and analysis. He graduated from MIT with a degree in Management of Information Technology.
Back to BLOG
Agentic Data Engineering: What It Is and How Genesis Automates the Full Pipeline Lifecycle
.jpg)
.jpg)
.jpg)
Stay in the Fast Lane
News and product updates in Agentic AI for enterprise data teams.
Oops! Something went wrong while submitting the form.

Back to top
share
TL;DR Genesis is an autonomous multi-agent system that manages the complete data pipeline lifecycle — from source connection through execution, monitoring, and failure resolution — deployed natively inside your existing cloud environment. Unlike general-purpose coding assistants, Genesis is purpose-built for data engineering — with native system connectivity, pre-built data engineering skills and methodologies, and autonomous end-to-end pipeline management. Genesis customers report 60–80% reduction in manual data engineering effort, pipeline delivery acceleration of 3–10×, and at least $180K–$340K in annual savings per deployment.
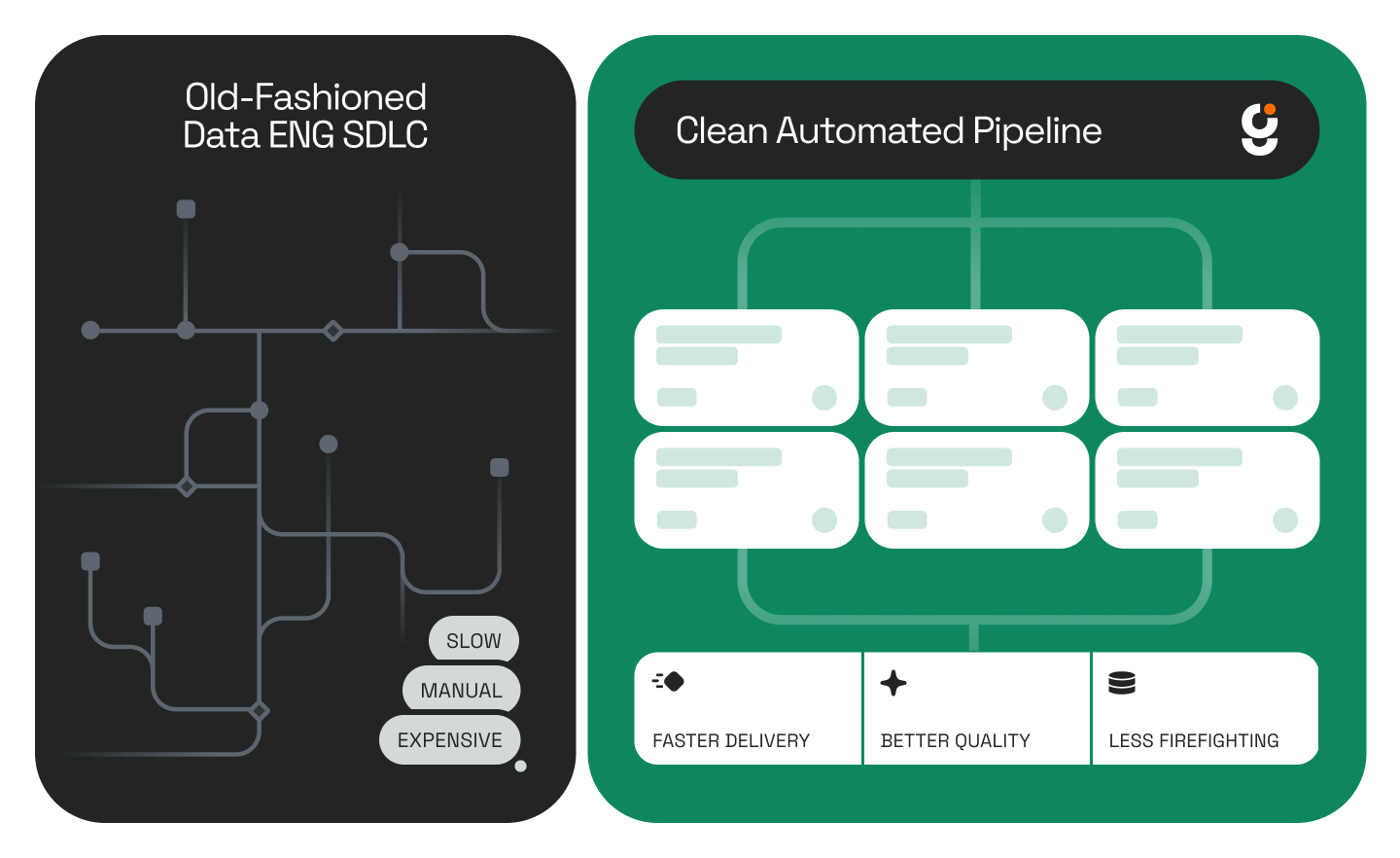
Enterprise data teams face a compounding problem: growing infrastructure demands, flat headcount, and AI tools that automate fragments of the workflow but not the whole. The market offers coding assistants, platform-native bots, and traditional ETL — none of which solve the core challenge of autonomous end-to-end pipeline management.
Genesis was built to close that gap. Not as another coding assistant, but as a fully autonomous data engineering agent that manages the complete pipeline lifecycle, living and running directly inside your existing cloud or data environment, rigorously following your data teams existing methodologies and processes, using your existing tools and permission/RBAC structures.
What Is Agentic Data Engineering?
Definition: Agentic data engineering is the practice of deploying autonomous AI agents to manage the complete data pipeline lifecycle — from source connection and schema discovery through pipeline construction, execution, monitoring, and failure resolution — without requiring human intervention at each step. Unlike AI coding assistants, which generate code on demand, agentic data engineering systems operate persistently within enterprise cloud environments, building and maintaining enterprise data context, and institutional memory, and executing structured, auditable workflows.
This is a distinct category from general AI assistance. Agentic data engineering systems are purpose-built for operational data workflows, not code generation. The difference matters: a coding assistant produces an artifact; an agentic data engineering system owns the outcome.
What Genesis Is
Genesis is an autonomous multi-agent system for enterprise data engineering. It deploys natively inside your cloud and/or data infrastructure — as a Snowflake Native App, within your AWS or Azure VPC, on Databricks, or via Docker — meaning your data never leaves your security perimeter. It connects to your schemas, pipelines, source systems, and tools, then builds, executes, monitors, and repairs data pipelines without requiring manual intervention at each step.
Genesis writes code — but that’s not the point. Unlike general-purpose coding assistants built for software engineering broadly, Genesis is purpose-built for the data engineering lane: it comes with native connectivity to data systems, pre-built skills and Blueprints specific to pipeline workflows, and the ability to orchestrate the full lifecycle autonomously. That specialization is what enables it to move faster, repeat reliably, and operate in production with confidence. Genesis also can delegate work down to coding assistants such as Claude Code or Codex, and to despoke in-platform agents such as Databricks Genie or Snowflake Cortex Code (Coco).
How Genesis Works

01 — Agent Onboarding
Genesis agents come pre-built with skills focused on the platforms and tools data engineers use. During onboarding, they connect to your Git repositories, databases, documents, and data catalog to construct the Context Graph — a digital twin of your enterprise's data flows and the institutional knowledge behind them.
Context Graph defined: A Context Graph is Genesis's structured representation of an enterprise's complete data environment — including pipeline architectures, source system relationships, schema history, and the institutional reasoning behind past architectural decisions. It enables agents to operate intelligently in your environment from day one without a ramp-up period.

02 — Blueprint Identification and Action
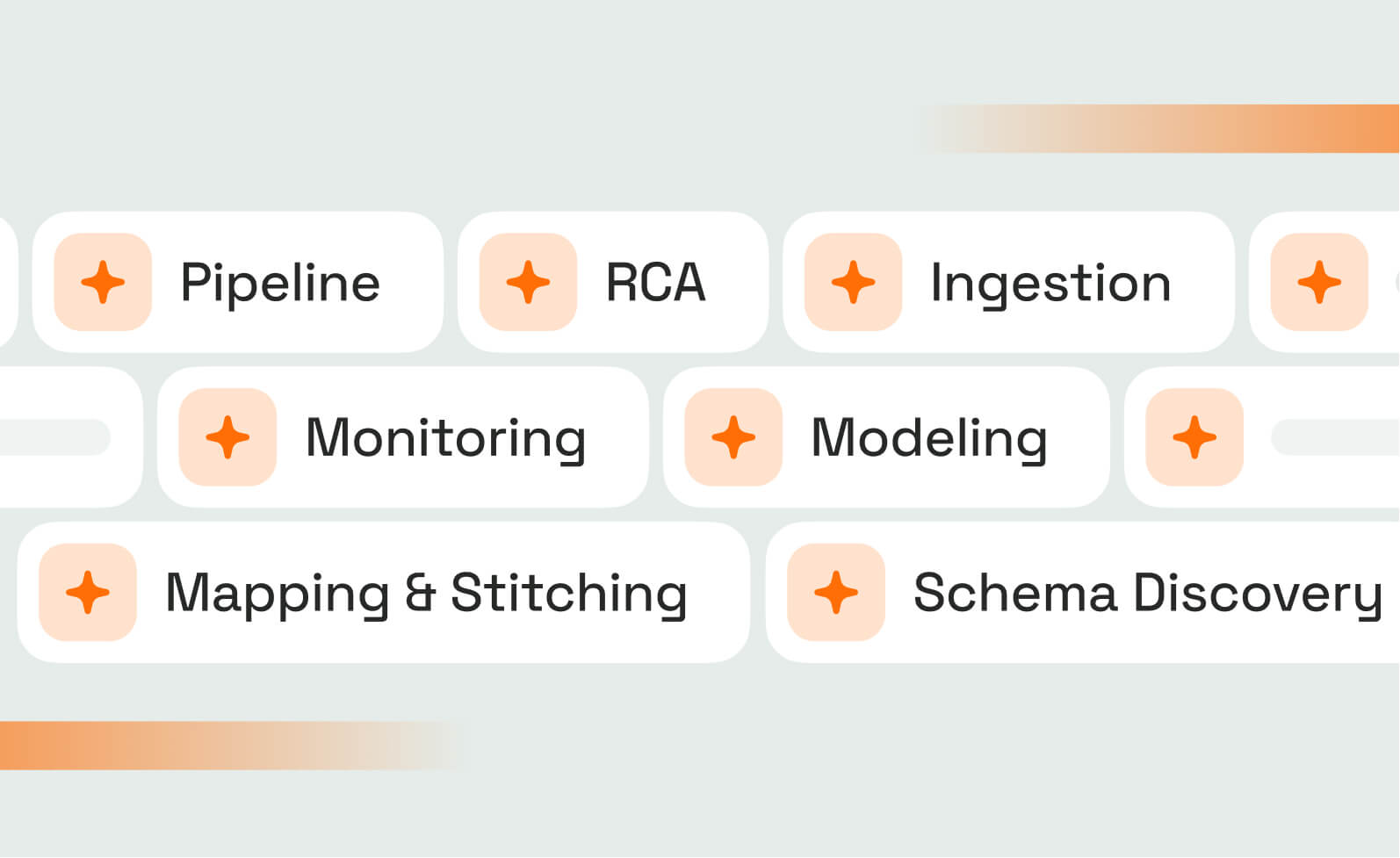
For each use case — pipeline development, ingestion, monitoring, schema discovery, data modeling, mapping and stitching, root cause analysis — Genesis identifies an existing Blueprint that fits, forks and edits an out of the box Blueprint, or builds a new bespoke one.
Blueprint defined: A Blueprint is a structured, reusable workflow definition that governs how Genesis agents execute a specific data engineering task. Blueprints define flexible execution paths with conditional logic and early exits, ensuring work is auditable without being rigid. Once a Blueprint is established, execution is deterministic and repeatable — this is what separates Genesis from probabilistic coding agents.
03 — Execute Missions and Tasks
Genesis aligns agents and human team members on a clear goal, scope, and success criteria. Work is broken into Missions and Tasks, which ensure each step is verified and tied back to the goal before proceeding.
Missions and Tasks defined: A Mission is a defined operational objective assigned to one or more Genesis agents — the 'what' and 'why' of a data engineering workstream. Tasks are the discrete, verifiable steps within a Mission. Every Task must meet its success criteria before the next begins. This structured accountability layer is what makes autonomous execution trustworthy in production.
Common Questions About Agentic Data Engineering
What is the difference between an AI coding assistant and an agentic data engineering platform?
An AI coding assistant — like Claude Code, Codex, GitHub Copilot or Cursor — generates and refines code on demand. It responds to prompts; it does not initiate work, monitor systems, or resolve failures autonomously. An agentic data engineering platform like Genesis operates persistently: it connects to source systems, detects schema drift, manages pipeline health, resolves failures, and maintains institutional memory across the entire data engineering lifecycle — without a human prompting each step. Genesis’s out of the box GUI, tool set, skill set, and Blueprint library is optimized for Data Engineering and Data Analysis versus open-ended software engineering.
Can AI agents replace data engineers?
Genesis reduces the number of data engineers an organization needs to achieve the same — or greater — pipeline throughput. Teams running Genesis can scale output without scaling headcount, reassigning engineers from high-volume operational work to architecture, business logic, and higher-judgment problems. It operates under human supervision with full auditability at every step. Genesis starts by doing the work that human Data Engineers don’t like doing or don’t generally perform with maximum rigor, and can expand from there.
How does Genesis deploy inside Snowflake, AWS, or Azure?
Genesis deploys as a Snowflake Native App directly within your Snowflake environment, within an AWS or Azure Virtual Private Cloud (VPC), on Databricks, or via Docker. In all cases, your data remains within your security perimeter — Genesis does not transmit data to external systems. This architecture satisfies enterprise data residency, compliance, and security requirements. Genesis agents can be granted roles and access via RBAC the same way such access is granted to the extant human data engineers.
What is autonomous pipeline monitoring?
Autonomous pipeline monitoring is the continuous, agent-driven observation of data pipeline health — including failure detection, schema drift identification, data quality checks, and root cause analysis — without requiring human initiation. Genesis agents monitor pipelines in real time and execute remediation workflows automatically when anomalies are detected, reducing mean time to resolution and eliminating manual triage.
How Genesis Compares to Alternatives
The enterprise data tooling market breaks into three categories, none of which solve the full operational data engineering problem on their own:
Platform-native agents (Snowflake Cortex, Databricks Assistant, Matillion Maia, etc.) are generally bounded by and optimized for their host platform. They lack broad visibility into cross-platform dependencies, project management context, or the institutional history behind architectural decisions. Genesis operates across your full environment regardless of where data lives, which generally spans across many enterprise data tools, platforms, work tracking, ticketing, and code/document repositories.
Coding agents (Claude Code, Copilot,, Cursor) generate and debug code effectively but are not optimized for for operational data engineering. They don't autonomously connect to source systems, monitor pipeline health, handle schema drift, manage failures, or maintain institutional memory. Assembling a full data engineering workflow from a coding agent requires building the orchestration layer yourself — which is, in practice, building Genesis from scratch. They also lack business-user facing GUIs and are optimized for software engineers.
Traditional ETL platforms handle pipeline construction but require significant manual configuration, lack AI-driven adaptability beyond introductory copilots, and don't offer autonomous failure resolution or cross-system institutional memory.
Proven Results Across Enterprise Data Teams
Aggregate impact: Genesis customers report an average of 60–80% reduction in manual data engineering effort, pipeline delivery acceleration of 3–10×, and $180K–$340K in initial annual savings per initial deployment (and will achieve even greater savings over time).
Who Genesis Is For
Genesis is designed for enterprise data teams running Snowflake, Databricks, AWS, Azure, or Docker environments who need to scale pipeline delivery without scaling headcount — particularly organizations managing:
- Legacy migrations requiring high-volume pipeline reconstruction
- High-frequency client data onboarding (financial services, SaaS platforms)
- Financial and alternative data ingestion where time-to-signal is critical
- Large backlogs of manual data engineering work with limited team capacity
The Bottom Line
The enterprise data engineering challenge is not a shortage of AI tools — it is a shortage of AI systems that operate across the full pipeline lifecycle, inside your security perimeter, with production-grade reliability and structured accountability. That is what agentic data engineering delivers. That is what Genesis is built for.
Glossary of Key Terms
Agentic Data Engineering: The use of autonomous AI agents to manage the complete data pipeline lifecycle without human intervention at each step. Distinct from AI-assisted coding or platform-native automation.
Context Graph: Genesis's structured digital twin of an enterprise data environment, encoding pipeline architectures, source relationships, schema history, and institutional decision-making context.
Blueprint: A structured, reusable workflow definition governing how Genesis agents execute a specific data engineering task. Deterministic and auditable once established.
Mission: A defined operational objective assigned to Genesis agents, specifying the goal, scope, and success criteria for a data engineering workstream.
Task: A discrete, verifiable step within a Mission. Each Task must meet defined success criteria before execution proceeds.
Platform-agnostic deployment: Genesis's ability to deploy natively within multiple cloud environments — Snowflake, AWS, Azure, Databricks, Docker — within the customer's security perimeter.
Stay in the Fast Lane
News and product updates in Agentic AI for enterprise data teams.
Oops! Something went wrong while submitting the form.


.png)
%201%20(1).jpg)
Keep Reading

.jpg)
%201%20(1).jpg)
.jpg)
.png)

.png)

.png)
.png)
.png)

.png)
Stay Connected!
Discover the latest breakthroughs, insights, and company news. Join our community to be the first to learn what’s coming next.
.png)