Back to BLOG
How Genesis Automates Data Pipeline Development in Hours

Stay in the Fast Lane
News and product updates in Agentic AI for enterprise data teams.
Oops! Something went wrong while submitting the form.

Back to top
share
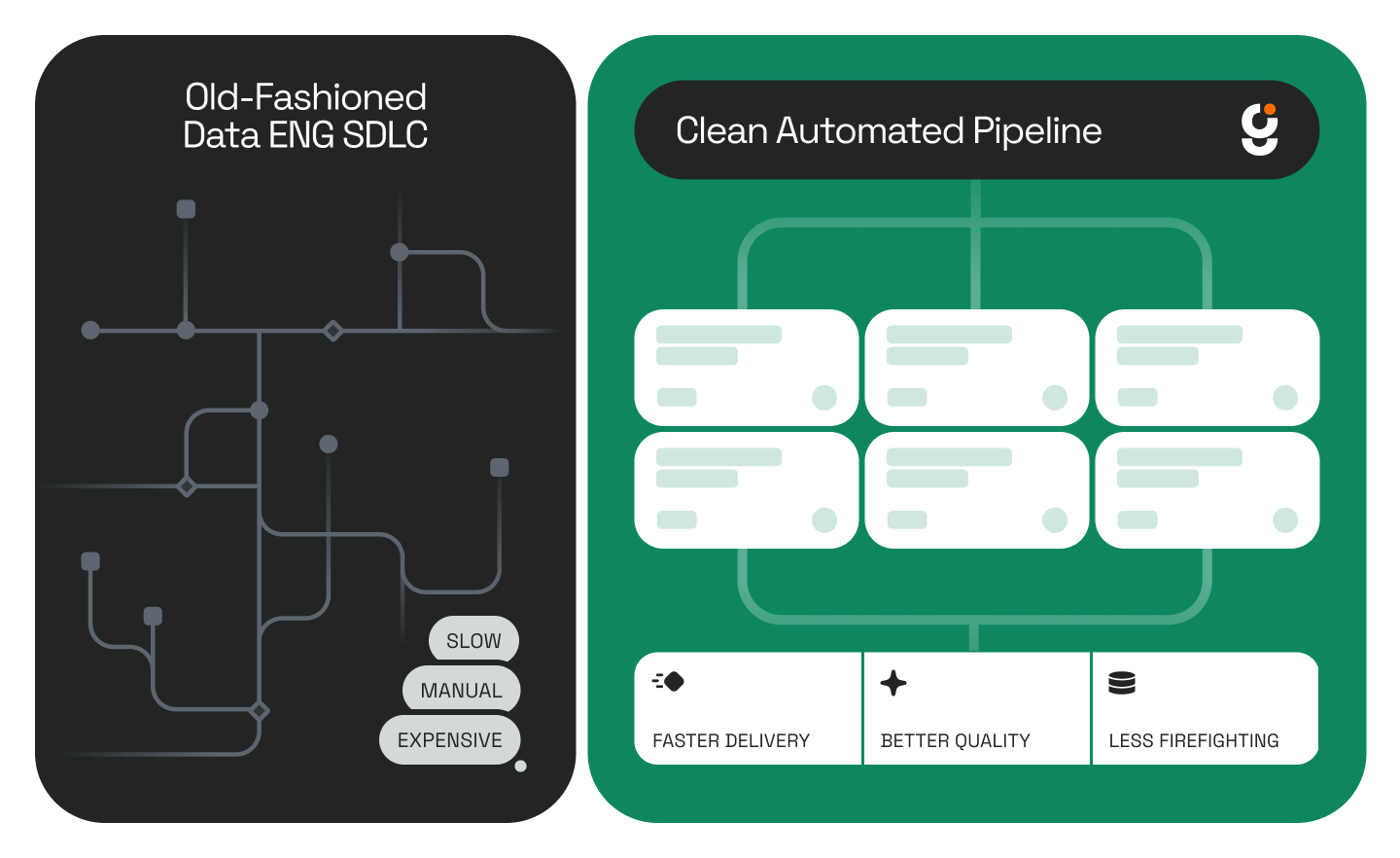
Transform B2B data engineering with Genesis: reduce pipeline development time and boost productivity.
Discover how Genesis transforms data pipeline development from months to hours. Learn to leverage its AI capabilities for analyzing, coding, and automating pipelines, enhancing team productivity and operational efficiency.
TL;DR
- Genesis automates data pipeline development by analyzing source data, proposing transformations, and coding pipelines with minimal human intervention, reducing development from months to hours
- Adoption follows four phases: assessment, controlled deployment, operational integration, and scaled autonomy, with each phase building capability before expanding scope
- Start with bounded pilots using well-structured data and common transformation patterns to demonstrate value while managing risk
- Governance is not optional: configure access controls, approval workflows, and audit logging before deployment to maintain security and compliance
- Autonomous means oversight, not absence: human effort shifts from routine coding to strategic review and exception handling, not elimination
Guide Orientation: What This Guide Covers
This guide provides a practical framework for adopting autonomous AI agents that transform data pipeline development from a months-long engineering effort into a process measured in hours. You will learn how Genesis automates data pipeline development through its core capabilities: analyzing source data, proposing transformations, and coding pipelines with minimal human intervention.
This content is designed for data engineering leaders, architects, and technical decision-makers in B2B enterprises evaluating automation solutions. By the end, you will understand the operational model for autonomous pipeline development, the decision points that determine successful adoption, and how to structure your team's transition.
This guide does not cover basic data engineering concepts or compare Genesis to manual development approaches in exhaustive detail. It assumes you already recognize the need for acceleration and are evaluating how to execute.
Why Autonomous Pipeline Development Matters Now
Data engineering teams face a structural problem. Demand for new pipelines consistently outpaces capacity to build them. Traditional development cycles require weeks of schema analysis, transformation logic design, testing, and deployment. Each pipeline becomes a project unto itself.
This bottleneck compounds as organizations scale their data operations. Delayed pipelines mean delayed insights, which translate directly into slower decision-making and missed opportunities. Meanwhile, engineering talent remains scarce and expensive.
The cost of inaction is not just slower delivery. It is accumulated technical debt, inconsistent data quality, and teams perpetually in reactive mode. Organizations that fail to address pipeline velocity will find themselves unable to support the analytics and AI initiatives their business units demand.
Core Concepts: Understanding Autonomous Data Agents
Before examining the adoption framework, establish clarity on the foundational concepts that distinguish autonomous pipeline development from traditional automation.
Autonomous Agents vs. Automation Scripts
Traditional automation executes predefined rules. Autonomous agents analyze context, propose solutions, and adapt to new scenarios. When Genesis automates data pipeline development, it does not simply run templates. It interprets source data structures, infers transformation requirements, and generates pipeline code tailored to your specific environment.
The Analysis-Proposal-Execution Loop
Autonomous pipeline development operates through a continuous cycle. The agent ingests source data, maps relationships and structures, proposes transformation logic, generates code, tests outputs, and monitors production performance. Human oversight occurs at decision points, not at every step.
Production-First Architecture
Unlike prototyping tools that require significant rework for production deployment, a production-first approach means generated pipelines are deployment-ready. They integrate with your existing Snowflake or Databricks infrastructure without requiring custom coding or extensive modification.
The Adoption Framework: Four Phases of Transformation
Successful adoption follows a structured progression. Each phase builds capability and confidence before advancing to broader deployment.
- Phase 1: Assessment and Alignment establishes organizational readiness and identifies initial use cases
- Phase 2: Controlled Deployment introduces autonomous agents to a bounded scope with clear success metrics
- Phase 3: Operational Integration expands coverage while establishing governance protocols
- Phase 4: Scaled Autonomy transitions to autonomous operation across the pipeline portfolio
These phases are not strictly sequential. Organizations may iterate between phases as they learn and adapt. The framework provides navigational structure, not rigid prescription.
Step-by-Step Breakdown
Step 1: Audit Your Current Pipeline Portfolio
Objective: Establish a clear baseline of existing pipeline complexity, development velocity, and maintenance burden.
Begin by cataloging your active pipelines. Document source systems, transformation complexity, update frequency, and current ownership. Identify which pipelines consume disproportionate engineering time, whether through initial development, ongoing maintenance, or frequent troubleshooting.
Quantify your current development cycle. How long does a typical pipeline take from request to production? Where do delays concentrate? Common bottlenecks include schema discovery, transformation logic design, testing cycles, and deployment approvals.
What to avoid: Do not attempt comprehensive documentation of every pipeline detail. Focus on patterns and categories rather than exhaustive inventories. Perfectionism at this stage delays progress without improving decisions.
Success indicators: You can articulate your average pipeline development time, identify your top maintenance burdens, and categorize pipelines by complexity tier.
Step 2: Select Initial Use Cases for Autonomous Development
Objective: Identify pipeline candidates that balance meaningful impact with manageable risk.
Ideal initial candidates share specific characteristics. They involve well-structured source data with clear schemas. They require common transformation patterns (filtering, aggregation, joins, type conversions). They are not mission-critical systems where any disruption carries severe consequences.
Avoid selecting either trivial pipelines (which prove little) or your most complex integrations (which introduce unnecessary risk). The goal is demonstrating capability while building organizational confidence.
Consider pipelines currently in the backlog. These represent unmet demand where acceleration delivers immediate value without disrupting existing operations.
What to avoid: Selecting use cases based solely on technical simplicity. The business value of accelerating a pipeline matters as much as its technical profile. A simple pipeline nobody needs proves nothing useful.
Success indicators: You have identified three to five pipeline candidates with clear business sponsors, defined success criteria, and manageable technical complexity.
Step 3: Configure Integration with Your Data Platform
Objective: Establish secure, governed connectivity between autonomous agents and your existing infrastructure.
Genesis integrates with platforms like Snowflake and Databricks through standard authentication and authorization mechanisms. Configure access controls that provide agents with sufficient permissions to analyze source data and deploy pipelines while maintaining security boundaries.
Establish a development environment where autonomous agents operate initially. This sandbox allows your team to observe agent behavior, validate outputs, and build familiarity before production deployment.
Define governance protocols. Who approves agent-proposed transformations? What review process applies before production deployment? How are agent actions logged and audited? These decisions should reflect your existing data governance standards while accommodating the speed of autonomous operation.
What to avoid: Granting overly broad permissions to accelerate setup. Security shortcuts create risk and undermine organizational trust in the automation approach.
Success indicators: Agents can access designated source systems, propose transformations, and deploy to your development environment. Audit logs capture all agent actions. Approval workflows are defined and tested.
Step 4: Execute Pilot Pipeline Development
Objective: Complete end-to-end autonomous pipeline development for selected use cases.
Initiate the autonomous development process for your first candidate pipeline. The agent will ingest source data, analyze structures and relationships, map fields to target schemas, and propose transformation logic. Review these proposals with your engineering team.
Observe how the agent handles ambiguity. When source data contains inconsistencies or unclear relationships, how does it surface these issues? What decisions does it make independently versus escalate for human input?
Execute the generated pipeline code in your development environment. Validate outputs against expected results. Document any discrepancies and the corrections required. This feedback improves agent performance and calibrates your team's expectations.
What to avoid: Expecting perfection on first execution. Autonomous agents learn and improve through feedback. Initial outputs may require adjustment. The measure of success is whether total time-to-production decreases significantly, not whether human review becomes unnecessary.
Success indicators: Pilot pipelines complete development in hours rather than weeks. Output data quality meets or exceeds manually developed equivalents. Your team understands the human-agent collaboration model.
Step 5: Establish Monitoring and Remediation Protocols
Objective: Ensure deployed pipelines maintain quality and performance with minimal manual intervention.
Autonomous agents do not stop at deployment. They monitor pipeline performance, detect anomalies, and remediate issues. Configure alerting thresholds that match your operational requirements. Define escalation paths for issues that exceed agent remediation capabilities.
Integrate agent monitoring with your existing observability stack. Pipeline health should be visible alongside other operational metrics your team already tracks.
Establish feedback loops. When agents remediate issues, capture these events for analysis. Patterns in remediation activity reveal opportunities for upstream improvements in source data quality or transformation logic.
What to avoid: Treating autonomous monitoring as a replacement for operational awareness. Agents handle routine issues. Your team maintains responsibility for understanding overall system health and addressing systemic problems.
Success indicators: Deployed pipelines maintain target uptime with reduced manual intervention. Remediation events are logged and reviewable. Your team spends less time on routine troubleshooting.
Step 6: Scale Autonomous Coverage
Objective: Expand autonomous development to additional pipeline categories while maintaining quality and governance.
With pilot success established, identify the next tier of pipeline candidates. Increase complexity gradually. Move from well-structured sources to more heterogeneous data. Expand from common transformation patterns to domain-specific logic.
As coverage expands, refine your governance model. Determine which pipeline categories can proceed with minimal human review and which require closer oversight. This tiered approach balances velocity with appropriate control.
Measure cumulative impact. Track total development time saved, maintenance burden reduced, and backlog cleared. These metrics justify continued investment and guide resource allocation.
What to avoid: Rushing to full automation before establishing confidence at each tier. Premature scaling introduces risk and can undermine organizational support if issues emerge.
Success indicators: Autonomous development covers an expanding percentage of your pipeline portfolio. Development velocity improvements are measurable and sustained. Governance protocols scale without becoming bottlenecks.
Practical Application: Scenario Comparison
Scenario A: New Data Source Integration
A business unit requests integration of a new SaaS application's data into your analytics environment. Traditional approach: two to four weeks for schema analysis, transformation design, development, testing, and deployment.
With autonomous development: The agent analyzes the source API or data export, maps fields to your target schema, proposes transformations, generates pipeline code, and deploys to development within hours. Your team reviews and approves. Production deployment follows within days, not weeks.
Scenario B: Legacy Pipeline Modernization
An aging pipeline built years ago requires modernization. Documentation is incomplete. The original developer has left. Traditional approach: extensive reverse-engineering before any modification can begin.
With autonomous development: The agent analyzes source data and current outputs, infers transformation logic, and proposes a modernized pipeline that produces equivalent results. Your team validates output parity before cutover.
Common Mistakes and How to Avoid Them
Organizations adopting autonomous pipeline development commonly stumble in predictable ways. Recognizing these patterns helps you avoid them.
Underinvesting in governance setup. Teams eager to demonstrate velocity skip governance configuration. This creates technical debt and security exposure that undermines long-term adoption.
Expecting zero human involvement. Autonomous does not mean unsupervised. The goal is shifting human effort from routine execution to strategic oversight and exception handling.
Measuring only speed. Development velocity matters, but data quality, operational reliability, and team satisfaction are equally important success indicators.
Isolating adoption within engineering. Successful adoption requires alignment with data governance, security, and business stakeholders. Engineering-only initiatives often stall at organizational boundaries.
What to Do Next
Begin with the audit described in Step 1. Document your current pipeline development cycle and identify your highest-impact candidates for autonomous development. This baseline enables meaningful measurement of improvement.
Engage stakeholders beyond engineering early. Data governance, security, and business leadership should understand the approach before deployment begins. Their input shapes governance protocols and builds organizational support.
Treat this guide as a reference rather than a checklist. Return to relevant sections as you progress through adoption phases. Your specific context will require adaptation of these principles to your environment.
The transition from months to hours does not happen overnight. It happens through deliberate, phased adoption that builds capability and confidence incrementally. Start with one pipeline. Learn. Expand.
Frequently Asked Questions
How does Genesis analyze source data without predefined schemas?
Genesis employs autonomous agents that ingest raw data and infer structure through a digital twin. The agents identify field types, relationships between entities, and data quality characteristics without requiring manual schema documentation. When ambiguity exists, the system surfaces these uncertainties for human review rather than making assumptions that could compromise data integrity.
What level of technical expertise do teams need to operate autonomous pipeline development?
Teams need data engineering fundamentals and familiarity with their target platforms (Snowflake, Databricks, or similar). They do not need to learn new tools, replace existing tools, or write pipeline code manually. The shift is from coding pipelines to reviewing agent proposals, configuring governance rules, and handling exceptions. Existing data engineering skills remain valuable but apply differently.
How do autonomous agents handle sensitive data and compliance requirements?
Agents operate within the access controls and permissions you configure. They do not bypass your existing security infrastructure. For compliance requirements like HIPAA, you define data handling rules that agents follow during transformation and deployment. Audit logs capture all agent actions for compliance documentation.
Can autonomous development handle complex transformation logic beyond basic ETL?
Yes. While initial adoption typically focuses on common patterns, autonomous agents can propose and implement complex transformations including multi-table joins, conditional logic, aggregations, and data quality rules. The key is graduated complexity. Start with simpler use cases and expand as you validate agent capabilities against your specific requirements.
What happens when an autonomous agent encounters data it cannot process correctly?
Agents are designed to recognize their limitations. When source data presents patterns outside their confidence threshold, they escalate to human review rather than proceeding with uncertain transformations. This transparency ensures you maintain control over data quality decisions while benefiting from automation where agents perform reliably.
How does this approach integrate with existing CI/CD and DevOps workflows?
Generated pipeline code deploys through your existing infrastructure. Agents produce artifacts compatible with standard deployment tools and version control systems. You retain your current approval workflows, testing gates, and deployment processes. The automation accelerates development; it does not replace your operational governance.
Stay in the Fast Lane
News and product updates in Agentic AI for enterprise data teams.
Oops! Something went wrong while submitting the form.
.jpg)
.png)


Keep Reading

.png)
.png)
.png)
.jpg)
.png)
%201%20(1).jpg)
.png)
%201%20(1).jpg)


.png)
Stay Connected!
Discover the latest breakthroughs, insights, and company news. Join our community to be the first to learn what’s coming next.
.png)